When it comes to machine learning, there are a wide range of models available in the field. With no doubt, it will be a huge project in terms of efforts and time if someone tries to walk them through. So I've been thinking it may be a good idea if we get them work first with example Python codes. As to concept, underlying math, business scenarios, profits, concerns etc., we can pick up with more researches later when we work on a specific business case. The merit to do this is that we get to know, these models, probably just a little, and we can gain hands-on programming in the first place. It would lay a foundation for further development as needed.
I happened to read a book, Python Statistics & Machine Learning Mastering Handbook, authored by Team Karupo. The book introduces a bunch of models with concise texts and examples covering supervised and unsupervised and deep learning estimators.
Inspired by it, I planned to build a series of models at once that can be flexibly selected and visualize their performance on the same graph. Moreover, I would like to approach it from the engineering angle and make the process as simple as we feed the input dataset, then get the visual evaluation results, like the graph shown below. (Please be noted that the process of developing and tuning a model is not the subject we are going to address here. If you are interested in that, please check out Machine Learning - Build A GradientBoostingRegressor Model for more details. )
For each model, we'll do the prediction for both the test data and the training data, and calculate their accuracy scores as well. Then display them on the chart where a model relates to a solid circle. X axis represents the accuracy score for the training data, whereas Y axis represents the accuracy score for the test data.
At the same time, use the score() method provided by the model to get the score for this specific case, texted right above the circle.
Models to Be Compared
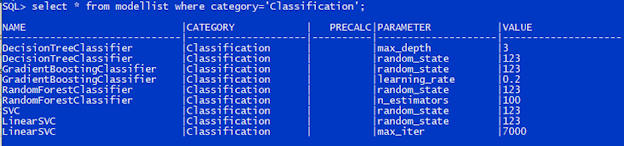
Models to be compared are stored in the table ModelList, as shown below.
Name field bears the name of a model.
Category field defines which group the model belongs to, either Classification or Regression.
Parameter and Value fields define parameters to be passed to the model in its creation. Parameter field holds the name of the parameter, and Value field carries the value associated with that parameter. You can add as many parameters as you need for a model. On the other hand, if you don't specify any parameters for a model, the model will take the default parameters.
PreCalc is an indicator showing if we need to carry out extra calculations on the input data before it is passed to a model. For example, we should use a polynomial to transform the data before feed it into Lasso regression model. We'll discuss it more in another blog Machine Learning - Build And Compare Regression Models.
Dataset
The dataset is kept in a table called DatasetCls, which consists of only the feature columns and the label column. Any descriptive columns have to be removed. Additionally, the label column has to appear last. DatasetCls can be either a normal table or an external table.
That is all, we don't have more rules for it.
Dataset Generated by make_classification()
Main Flow
The main flow, illustrated on the following diagram, is implemented in function CompareClassificationModels() that you can find in the latter section Appendix: Source Code.
Please be noted that we'll standardize the training data and the test data before feed them into the models.
How Are Models Created?
Model instantiation is implemented in class ClassifierFactory packaged in modelfactory.py. Please refer to Appendix: Source Code section.
The factory method newclassifier() creates and returns a model with specified parameters. The models defined inside the class are all the classifiers that this factory can produce so far. You can add or delete models based on your needs.
The method execute() will call fit() and predict() and score() on the model. Additionally, it will call accuracy_score() to evaluate the model's performance on the given datasets.
How to Add a Model?
This is pretty straightforward. We can get it done by appending a record to the table ModelList. For example, we would like to add LogisticRegression to the list and specify random_state parameter at the same time. So we can execute the following SQL statement.
insert into modellist values('LogisticRegression', 'Classification', null, 'random_state', '123');
Then we re-run the program, as you can see, LogisticRegression appears on the graph.
How to Switch the Dataset?
For example, we would like to use the wine dataset coming with sklearn. If we have the csv file on hand, we can create an external table using the SQL script below. If the script doesn't work in your environment, please double check if your csv file has the right encoding.
create table datasetcls (
free_sulfur_dioxide number,
total_sulfur_dioxide number,
default directory externalfile
records delimited by newline
location ('winequality-red.csv')
Wine Dataset
We can do the same for Iris dataset.
Iris Dataset
For the dataset processing, we used the hard-coded parameters. Obviously there is more room for improvements. In response to needs in the field, surely we can add more customized functionalities.
Additionally, the similar work for the regression models will be undertaken and summarized in another blog.
Reference
Python Statistics & Machine Learning Mastering Handbook Team Karupo
Choosing the right estimator
Machine Learning - Build A GradientBoostingRegressor Model
Machine Learning - Build And Compare Regression Models
Appendix: Source Code
CompareClassificationModels()
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import oracledb
import logging
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from modelfactory import ClassifierFactory
def CompareClassificationModels():
"""
The function instantiates a series of classification models pre-defined in a table
and fit the models and computes the predictions for a specific dataset
and visualize the results.
:parameter:
No parameters are required.
:raise:
An oracledb.Error will be raised if anything goes wrong with the database.
:return:
This function doesn't return a value.
"""
# ------------------------------------------------------------------
# configure a logger
# ------------------------------------------------------------------
format = '%(asctime)s %(levelname)-10s [%(threadName)s] [%(module)s] [%(funcName)-30s] %(message)s'
logger = logging.getLogger('modellogger')
handler = logging.StreamHandler()
fmt = logging.Formatter(format)
handler.setFormatter(fmt=fmt)
logger.setLevel(logging.DEBUG)
logger.addHandler(handler)
logger.info('process starts')
# ------------------------------------------------------------------
# load the list of models and the dataset from the database
# ------------------------------------------------------------------
model_columns = ['Name', 'Category', 'PreCalc', 'Parameter', 'Value']
sqlmodel = "select * from modellist where category='Classification'"
sqldata = 'select * from datasetcls'
try:
with oracledb.connect(user="test", password='1234', dsn="localhost/xepdb1") as conn:
with conn.cursor() as cursor:
df_model = pd.DataFrame(cursor.execute(sqlmodel), columns=model_columns)
df_data = pd.DataFrame(cursor.execute(sqldata))
except oracledb.Error as e:
logger.error(f'Failed to fetch data from the database ({str(e)})')
return
logger.debug(f"list of the models\n{df_model}")
logger.debug(f"head of the dataset\n{df_data.head()}")
# ------------------------------------------------------------------
# data pre-processing
# ------------------------------------------------------------------
df_data = df_data.dropna()
# separate the dataset into features and labels
x, y = df_data.iloc[:, 0:-1], df_data.iloc[:, -1]
logger.debug(f"the features\n{x}")
logger.debug(f"the labels\n{y}")
#
# default parameters for dataset
test_size = 0.3
standardize = True
random_state = 123
# ------------------------------------------------------------------
# prepare the training dataset and the test dataset, standardize
# ------------------------------------------------------------------
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=test_size, random_state=random_state)
if standardize:
logger.info('Standardize the training and test datasets')
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
# ------------------------------------------------------------------
# create and fit and evaluate the models
# ------------------------------------------------------------------
model_list = df_model.Name.unique().tolist()
eval_res = []
if len(model_list) > 0:
model_list.sort()
mf = ClassifierFactory()
for name in model_list:
# create a model
model, desc = mf.newclassifier(name, df_model)
if model is not None:
logger.info(desc)
# execute fit, predict, evaluation
score_model, acc_train, acc_test = mf.execute(model, x_train, y_train, x_test, y_test)
eval_res.append([name, score_model, acc_train, acc_test])
logger.info(f' [Score: {score_model} Accuracy (Training): {acc_train} Accuracy (Test): {acc_test}]')
else:
logger.warning(desc)
score_model, acc_train, acc_test = None, None, None
logger.warning(f' [Score: {score_model} Accuracy (Training): {acc_train} Accuracy (Test): {acc_test}]')
# ------------------------------------------------------------------
# visualize the evaluation results
# ------------------------------------------------------------------
if len(eval_res) > 0:
logger.info('Visualize the evaluation results')
columns = ['Model', 'Score', 'Accuracy (Training)', 'Accuracy (Test)']
eval_res.sort()
df = pd.DataFrame(eval_res, columns=columns)
logger.debug(f"evaluation results\n{df}")
plt.grid(which='major')
#
# reference
xr = np.array(
[round(pd.DataFrame.min(df.iloc[:, 2:3]) - 0.05, 1), round(pd.DataFrame.max(df.iloc[:, 2:3]) + 0.05, 1)])
yr = xr.copy()
plt.plot(xr, yr, color='#D2D5D1')
sns.scatterplot(
data=df,
x='Accuracy (Training)',
y='Accuracy (Test)',
marker='o',
hue=df['Model']
)
plt.plot()
dev = (xr.max() - xr.min()) / 100.0
for eval in df.values:
score = round(eval[1], 2)
x = eval[2] + dev
y = eval[3] + dev
plt.text(x, y, score)
plt.legend(loc='best')
plt.suptitle('Compare Classification Models')
plt.show()
else:
logger.info('No evaluation results are available for visualization')
logger.info('process finishes')
modelfactory.py
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
class ClassifierFactory():
__dtc = 'DecisionTreeClassifier'
__gbc = 'GradientBoostingClassifier'
__lrc = 'LogisticRegression'
__rfc = 'RandomForestClassifier'
__svc = 'SVC'
__svl = 'LinearSVC'
@property
def dtc(self):
return self.__dtc
@property
def gbc(self):
return self.__gbc
@property
def lrc(self):
return self.__lrc
@property
def rfc(self):
return self.__rfc
@property
def svc(self):
return self.__svc
@property
def svl(self):
return self.__svl
def newclassifier(self, name, params):
"""
Acting as a factory method, new a classification model with the parameters specified by params.
:param name: str,
Name of the model to be instantiated.
:param params: pandas.DataFrame,
Parameters passed to the model in the creation.
Contains at least Name and Parameter and Value columns.
:return:
model: object, Instance of the model |
desc: str, description of the model
"""
# random_state for DecisionTreeClassifier, GradientBoostingClassifier
# RandomForestClassifier, SVC, LinearSVC
random_state = 0
# max_depth for DecisionTreeClassifier
max_depth = None
# learning_rate for GradientBoostingClassifier
learning_rate = 0.2
# n_estimators for RandomForestClassifier
n_estimators = 100
# max_iter for LinearSVC
max_iter = 5000
# DecisionTreeClassifier
if name == self.dtc:
df_dtc = params.loc[params.Name == self.dtc, :]
if len(df_dtc) > 0:
if 'max_depth' in df_dtc.Parameter.unique():
max_depth = int(df_dtc.query("Parameter=='max_depth'").Value.tolist()[0])
if 'random_state' in df_dtc.Parameter.unique():
random_state = int(df_dtc.query("Parameter=='random_state'").Value.tolist()[0])
desc = f'{name}(max_depth={max_depth}, random_state={random_state})'
model = DecisionTreeClassifier(max_depth=max_depth,
random_state=random_state
)
# GradientBoostingClassifier
elif name == self.gbc:
df_gbc = params.loc[params.Name == self.gbc, :]
if len(df_gbc) > 0:
if 'random_state' in df_gbc.Parameter.unique():
random_state = int(df_gbc.query("Parameter=='random_state'").Value.tolist()[0])
if 'learning_rate' in df_gbc.Parameter.unique():
learning_rate = float(df_gbc.query("Parameter=='learning_rate'").Value.tolist()[0])
desc = f'{name}(random_state={random_state}, learning_rate={learning_rate})'
model = GradientBoostingClassifier(random_state=random_state,
learning_rate=learning_rate
)
# LogisticRegression
elif name == self.lrc:
df_lrc = params.loc[params.Name == self.lrc, :]
if len(df_lrc) > 0:
if 'random_state' in df_lrc.Parameter.unique():
random_state = int(df_lrc.query("Parameter=='random_state'").Value.tolist()[0])
desc = f'{name}(random_state={random_state})'
model = LogisticRegression(random_state=random_state
)
# RandomForestClassifier
elif name == self.rfc:
df_rfc = params.loc[params.Name == self.rfc, :]
if len(df_rfc) > 0:
if 'n_estimators' in df_rfc.Parameter.unique():
n_estimators = int(df_rfc.query("Parameter=='n_estimators'").Value.tolist()[0])
if 'random_state' in df_rfc.Parameter.unique():
random_state = int(df_rfc.query("Parameter=='random_state'").Value.tolist()[0])
desc = f'{name}(n_estimators={n_estimators}, random_state={random_state})'
model = RandomForestClassifier(n_estimators=n_estimators,
random_state=random_state
)
# SVC
elif name == self.svc:
df_svc = params.loc[params.Name == self.svc, :]
if len(df_svc) > 0:
if 'random_state' in df_svc.Parameter.unique():
random_state = int(df_svc.query("Parameter=='random_state'").Value.tolist()[0])
desc = f'{name}(random_state={random_state})'
model = SVC(random_state=random_state
)
# LinearSVC
elif name == self.svl:
df_svl = params.loc[params.Name == self.svl, :]
if len(df_svl) > 0:
if 'random_state' in df_svl.Parameter.unique():
random_state = int(df_svl.query("Parameter=='random_state'").Value.tolist()[0])
if 'max_iter' in df_svl.Parameter.unique():
max_iter = int(df_svl.query("Parameter=='max_iter'").Value.tolist()[0])
desc = f'{name}(random_state={random_state}, max_iter={max_iter})'
model = LinearSVC(random_state=random_state,
max_iter=max_iter
)
# Undefined
else:
desc = f'{name} is not implemented as of now'
model = None
return model, desc
def execute(self, model, x_train, y_train, x_test, y_test):
"""
Calls fit and predict and score on the model.
Computes accuracy score for the training data and the test data
:param model: instance of the model
:param x_train: the training features
:param y_train: the training labels
:param x_test: the test features
:param y_test: the test labels
:return: score_model: float, score of the test data |
acc_train: float, accuracy score of the training data |
acc_test: float, accuracy score of the test data
"""
score_model = None
acc_train = None
acc_test = None
if model is not None:
# learning
model.fit(x_train, y_train)
# predict
y_test_pred = model.predict(x_test)
y_train_pred = model.predict(x_train)
# evaluate
score_model = model.score(x_test, y_test)
acc_train = accuracy_score(y_train, y_train_pred)
acc_test = accuracy_score(y_test, y_test_pred)
return score_model, acc_train, acc_test











No comments:
Post a Comment