As to handle data sources inside it, Tableau provides a bunch of means to process them, such as join, union, relationships, blending and etc. Relationships was newly introduced in the late version, Tableau 2020.2, which builds a logical layer on data source. Since it is not the topic for this post, so let's skip it at this point. Data blending is particularly useful when you use two data sources that have different level of detail in the same view. Let's save words and get down to work now.
In this example, we will explore the sales performance by comparing actual sales against goals by branch. The primary data source is the actual sales by representative. The secondary data source defines the sales goal by branch. They share Region, Branch Code, Branch, Fiscal Year attributes, as shown in the below screenshots.


Now, let's define the blending relationship for the above data sources. After you select the [Goal (datasource)] as the secondary one, Tableau automatically identified the key fields for blending because they share the same field names.

We drag [Fiscal Year], [Region] and [Branch] from the primary data source to the Rows tab in the view. Then add [Sales] and [Goal] to the Column tab, from the two data source respectively. Choose [bullet graphs] from Show Me menu. Additionally, we add [Product Category] to Color tab and add [Representative] to Detail tab so that the view level of detail is intentionally brought down to the finest level which is same as the primary data source.

It looks like the goals are set too high so only a few branches performed well. Let's take a look at what actually happened behind the scene. Right click on the view and select View Data menu, we can see the blended dataset used for this view.
The goals come to every row when the key fields, [Fiscal Year], [Region], [Branch], match with each other in the blended data sources. We use the first row as an example. The sales goal for branch Aichi is set as 4,800 in 2022. After blended, it appears in every record of the branch's Representatives.
This is how data blending works. You can find the changes when you add or remove the blending key fields.

As a result, the goal of a branch is multiplied by (# of Product Category * # of Representatives) when it is aggregated in the view, which is not the result we expected.
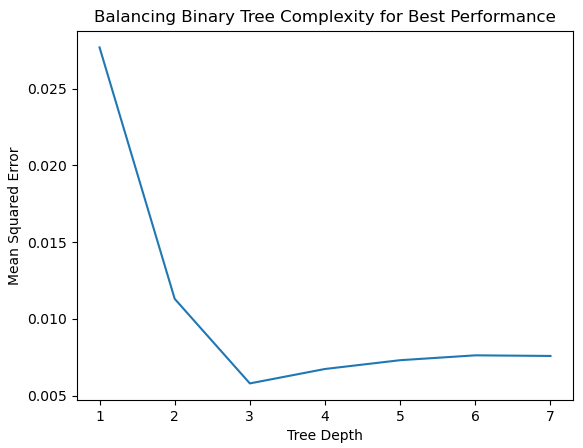
To fix it, we count the duplicates for each branch using a LOD expression, as the diagram shows below.

Then simply divide the sum of Goal by the count of duplicates in the view. The expected result came out as follows.