The credit goes to Dr. Michael Bowles, the author of Machine Learning in Python.
Mike illustrated how to train a decision tree in his book in such an easy-understanding way that I am excited to share it. Here I redo the examples step by step but use a slightly different data set. I also rewrote a part of the codes by replacing the loop calculations for arrays with Numpy functions.
In the model training, either of Sum Squared Error (SSE) or Mean Squared Error (MSE) is employed to measure the model's performance. Moreover, we change the 2 main variables as below to see how well it works:
- Depth of tree
- Size of training data
Train a Simple Decision Tree
import numpy as np
import matplotlib.pyplot as plot
from sklearn import tree
from sklearn.tree import DecisionTreeRegressor
def simpleTree():
#
# Generate a simple data set for the training
# x is between -0.5 and 0.5 incremented by 0.01
# y is equal to x + a random number generated by a gamma distribution
xPlot = np.round(list(np.arange(-0.5, 0.51, 0.01)), 2)
#
# x needs to be list of lists while using DecisionTreeRegressor
x = [[s] for s in xPlot]
#
# y has a gamma random added to x
np.random.seed(1)
y = xPlot + np.random.gamma(0.3, 0.1, len(xPlot))
#
# Decision tree with Depth = 1
simpleTree1 = DecisionTreeRegressor(max_depth=1)
simpleTree1.fit(x, y)
#
# Draw the tree. Use the following command to generate a png image
# dot -Tpng simpleTree1.dot - o simpleTree1.png
with open("simpleTree1.dot", 'w') as f:
f = tree.export_graphviz(simpleTree1, out_file=f)
#
# Compare predicted values by the tree against true values
yHat = simpleTree1.predict(x)
plot.subplot(221)
plot.plot(xPlot, y, label='true y')
plot.plot(xPlot, yHat, label='Tree Prediction', linestyle='--')
plot.legend(bbox_to_anchor=(1, 0.23))
plot.title('Depth = 1')
plot.axis('tight')
plot.xlabel('x')
plot.ylabel('y')
#
# Decision tree with Depth = 2
simpleTree2 = DecisionTreeRegressor(max_depth=2)
simpleTree2.fit(x, y)
#
# Draw the tree
with open("simpleTree2.dot", 'w') as f:
f = tree.export_graphviz(simpleTree2, out_file=f)
#
# Compare predicted values by the tree against true values
yHat = simpleTree2.predict(x)
plot.subplot(222)
plot.plot(xPlot, y, label='True y')
plot.plot(xPlot, yHat, label='Tree Prediction', linestyle='--')
plot.legend(bbox_to_anchor=(1, 0.2))
plot.title('Depth = 2')
plot.axis('tight')
plot.xlabel('x')
plot.ylabel('y')
#
# Split point calculations - try every possible split point to find the best one
# sse stands for sum squared errors
sse = []
xMin = []
mysse = []
for i in range(1, len(xPlot)):
#
# Divide list into points on left and right of split point
lhList = list(xPlot[0:i])
rhList = list(xPlot[i:len(xPlot)])
#
# Calculate sum squared errors on left and right
lhSse = np.var(lhList) * len(lhList)
rhSse = np.var(rhList) * len(rhList)
#
# Add sum of left and right to the error list
sse.append(lhSse + rhSse)
xMin.append(max(lhList))
minSse = min(sse)
idxMin = sse.index(minSse)
print(f'Index: {idxMin} min x:{xMin[idxMin]}')
print(sse)
plot.subplot(223)
plot.plot(range(1, len(xPlot)), sse)
plot.xlabel('Split Point Index')
plot.ylabel('Sum Squared Error')
plot.title('SSE vs Split Point Location')
#
# Decision tree with Depth = 6
simpleTree6 = DecisionTreeRegressor(max_depth=6)
simpleTree6.fit(x, y)
#
# More than 100 nodes were generated
# Among them were 50 leaf nodes
with open("simpleTree6.dot", 'w') as f:
f = tree.export_graphviz(simpleTree6, out_file=f)
#
# Compare predicted values by the tree against true values
yHat = simpleTree6.predict(x)
plot.subplot(224)
plot.plot(xPlot, y, label='True y')
plot.plot(xPlot, yHat, label='Tree Prediction', linestyle='--')
plot.legend(bbox_to_anchor=(1, 0.2))
plot.title('Depth = 6')
plot.axis('tight')
plot.xlabel('x')
plot.ylabel('y')
plot.show()
Binary Decision Tree with Depth = 1

Binary Decision Tree with Depth = 2

Comparisons

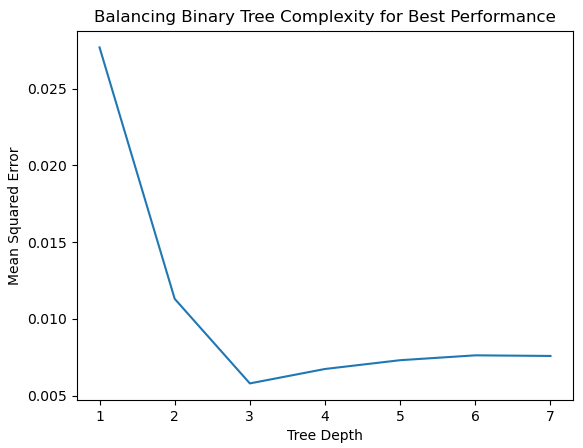
Use Cross-validation to Find the Decent Depth with Best Performance
When you increase the depth of tree, you may achieve a better performance. However, it doesn't mean a larger depth, a better performance. You will need to avoid overfitting as demonstrated by the example below. Be noted that important variables are split near the top of the tree in binary decision trees.
import numpy as np
import matplotlib.pyplot as plot
from sklearn.tree import DecisionTreeRegressor
def simpleTreeCV():
#
# Generate a simple data set for the training
# x is between -0.5 and 0.5 incremented by 0.01
# y is equal to x + a random number generated by a gamma distribution
xPlot = np.round(list(np.arange(-0.5, 0.51, 0.01)), 2)
#
# x needs to be list of lists while using DecisionTreeRegressor
x = [[s] for s in xPlot]
#
# y has a gamma random added to x
np.random.seed(1)
y = xPlot + np.random.gamma(0.3, 0.1, len(xPlot))
#
# Fit trees with the depth increased from 1 to 7 step by step
# and determine which performs best using x-validation
depthList = [1, 2, 3, 4, 5, 6, 7]
xvalMSE = []
nxval = 10
nrow = len(x)
for iDepth in depthList:
oosErrors = 0
#
# Build cross validation loop to fit tree and
# evaluate on the test data set
for ixval in range(nxval):
#
# Prepare test and training data sets
idxTest = [a for a in range(nrow) if a%nxval == ixval%nxval]
idxTrain = [a for a in range(nrow) if a%nxval != ixval%nxval]
xTrain = [x[r] for r in idxTrain]
yTrain = [y[r] for r in idxTrain]
xTest = [x[r] for r in idxTest]
yTest = [y[r] for r in idxTest]
#
# Train tree of appropriate depth and find the differences
# between the predicted output and the true output
treeModel = DecisionTreeRegressor(max_depth=iDepth)
treeModel.fit(xTrain, yTrain)
treePrediction = treeModel.predict(xTest)
error = np.subtract(yTest, treePrediction)
#
# Accumulate squared errors
oosErrors += sum(np.square(error))
#
# Average the squared errors and accumulate by tree depth
mse = oosErrors / nrow
xvalMSE.append(mse)
#
# Show how the averaged squared errors vary against tree depth
plot.plot(depthList, xvalMSE)
plot.axis('tight')
plot.xlabel('Tree Depth')
plot.ylabel('Mean Squared Error')
plot.title('Balancing Binary Tree Complexity for Best Performance')
plot.show()




No comments:
Post a Comment